El servidor WebLogic implementa tecnolog�as de componentes y servicios J2EE. Las tecnolog�as de componentes J2EE incluyen servlets, p�ginas JSP, y JavaBeans Enterprise. Los servicios J2EE incluyen el acceso a protocolos de red, a sistemas de base de datos, y a sistemas est�ndares de mensajer�a. Para construir una aplicaci�n de servidor WebLogic, debemos crear y ensamblar componentes, usando los APIs de sevicio cuando sean necesarios. Los componentes se ejecutan en contenedor Web del servidor WebLogic o el contenedor de EJB. Los contenedores proporcionan soporte para ciclo vital y los servicios definidos por las especificaciones J2EE de modo que los componentes que construyamos no tengan que manejar los detalles subyacentes.
Los componentes Web proporcionan la l�gica de presentaci�n para las aplicaciones J2EE basadas en navegador. Los componentes EJB encapsulan objetos y procesos del negocio. Las aplicaciones Web y los EJBs se construyen sobre servicios de aplicaci�n de J2EE, como JDBC, JMS (servicio de mensajer�a de Java), y JTA (API de Transaciones de Java).
La Figura 1-2 ilustra los contenedores de componentes y los servicios de aplicaci�n de WebLogic Server.
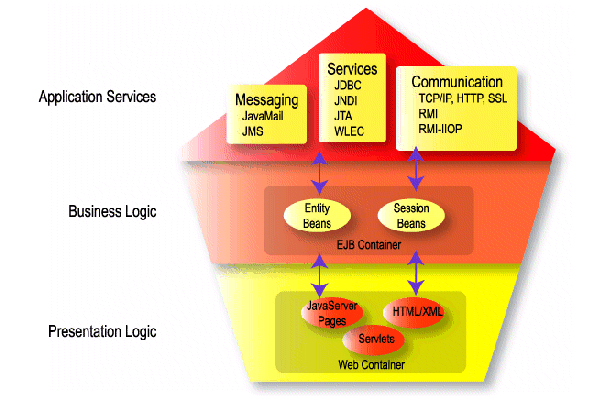
La siguientes secciones explican la capa de presetnaci�n, la l�gica del negocio y los servicios de aplicaci�n.
 �Capa L�gica de Presentaci�n
�Capa L�gica de Presentaci�n
La capa de presentaci�n incluye una l�gica de interface de usuario y de visualizaci�n de aplicaciones. La mayor�a de las aplicaciones J2EE utilizan un navegador web en la m�quina del cliente porque es mucho m�s f�cil que programas de cliente que se despliegan en cada ordenador de usuario. En este caso, la l�gica de la presentaci�n es el contenedor Web del servidor WebLogic. Sin embargo, los programas del cliente escritos en cualquier lenguaje de programaci�n, sin embargo, deben contener la l�gica para representar el HTML o su propia l�gica de la presentaci�n.
�Clientes de Navegador Web
Las aplicaciones basadas en Web construidas con tecnolog�as web est�ndar son f�ciles de acceder, de mantener, y de portar. Los clientes del navegador web son est�ndares para las aplicaciones de comercio electr�nico. En aplicaciones basadas en Web, el interface de usuario esr� representado por los documentos HTML, las p�ginas JavaServer (JSP), y los servlets. El navegador web contiene la l�gica para representar la p�gina Web en el ordenador del usuario desde la descripci�n HTML.
Las JavaServer Pages (JSP) y los servlets est�n muy relacionados. Ambos producen el contenido din�mico de la Web ejecutando el c�digo Java en el servidor WebLogic cada vez que se les invoca. La diferencia entre ellos es que JSP est� escrito con una versi�n extendida de HTML, y los servlets se escriben con el lenguaje de programaci�n Java.
JSP es conveniente para los dise�adores Web que conocen HTML y est�n acostumbrados al trabajo con un editor o dise�ador de HTML. Los Servlets, escritos enteramente en Java, est�n m�s pensados para los programadores Java que para los dise�adores Web. Escribir un servlet requiere un cierto conocimiento del protocolo HTTP y de la programaci�n de Java. Un servlet recibe la petici�n HTTP en un objeto request y escribe el HTML (generalmente) en un objeto result.
Las p�ginas JSP se convierten en servlets antes de que se ejecuten en el servidor WebLogic, por eso en �ltima instancia las p�ginas JSP y los servlets son distintas representaciones de la misma cosa. Las p�ginas JSP se despliegan en el servidor WebLogic la misma forma que se despliega una p�gina HTML. El fichero .jsp se copia en un directorio servido por WebLogic Server. Cuando un cliente solicita un fichero jsp, el servidor WebLogic controla si se ha compilado la p�gina o si ha cambiado desde la �ltima vez que fie compilada. Si es necesario llama el compilador WebLogic JSP, que genera el c�digo del servlet Java del fichero jsp, y entonces compila el c�digo Java a un fichero de clase Java.
�Clientes No-Navegadores
Un programa cliente que no es un navegador web debe suminstrar su propio c�digo para represetnar el interface de usuario. Los clientes que no son navegadores generalmente contienen su propia presentaci�n y l�gica de la representaci�n, dependiendo del servidor WebLogic solamente para la l�gica y el acceso al negocio o a los servicios backend. Esto los hace m�s dif�cil de desarrollar y de desplegar y menos convenientes para las aplicaciones basadas en Internet de comercio electr�nico que los clientes basados en navegador.
Los programas cliente escritos en Java pueden utilizar cualquier servicio del servidor WebLogic sobre Java RMI (Remote Method Invocatio). RMI permite que un programa cliente opere sobre un objeto del servidor WebLogic la misma forma que operar�a sobre un objeto local en el cliente. Como RMI oculta los detalles de las llamadas a tav�s de la red, el c�digo del cliente J2EE y el c�digo del lado del servidor son muy similares.
Los programas Java pueden utilizar las clases Swing de Java para crear interfaces de usuario poderosas y portables. Aunque usando Java podemos evitar problemas de portabilidad, no podemos utilizar los servicios del servidor WebLogic sobre RMI a menos que las clases del servidor WebLogic est�n instaladas en el cliente. Esto significa que lo clientes RMI de Java no son adecuados para el comercio electr�nico. Sin embargo, pueden usarse con eficacia en aplicaciones de empresariales en las cuales una red interna hace vieables la instalaci�n y el mantenimiento. Los programas cliente escritos en lenguajes distintos a Java y los programas clientes Java que no utilizan objetos del servidor WebLogic sobre RMI pueden tener acceso al servidor WebLogic usando HTTP o RMI-IIOP.
HTTP es el protocolo est�ndar para la Web. Permite que un cliente haga diversos tipos de peticiones a un servidor y pase par�metros al servidor. Un servlet en el servidor WebLogic puede examinar las peticiones del cliente, extraer los par�metros de la petici�n, y preparar una respuesta para el cliente, usando cualquier servicio del servidor WebLogic. Por ejemplo, un servlet puede responder a un programa cliente con un documento de negocio en XML. As� una aplicaci�n puede utilizar servlets como gateways a otros servicios del servidor WebLogic.
WebLogic RMI-IIOP permite que los programas compatibles con CORBA ejecuten Beans Enterprise del servidor WebLogic y clases RMI como objetos CORBA. El servidor RMI de WebLogic y los compiladores de EJB pueden generar IDL (Interface Definition Language) para las clases RMI y los Beans Enterprise. El IDL generado de esta manera se compila para crear los esqueletos para un ORB (Object Request Broker) y los trozos para el programa cliente. El servidor WebLogic analiza peticiones entrantes IIOP y las env�a al sistema de ejecuci�n RMI.
�Capa de L�gica de Negocio
Los JavaBeans Enterprise son componentes d ela l�gica de negocio para aplicaciones J2EE. El contenedor EJB de WebLogic Server almacenca beans enterprise, proporcionan el control del ciclo de vida y servicios como el caheo, la persistenca, y el control de transaciones. Aqu� tenemos tres tipos de beans enterprise: beans de entidad, beans de sesi�n y beans dirigidos por mensajes. Las siguientes secciones describen cada tipo en m�s detalle.
�Beans de Entidad
Un bean de entidad representa un objeto que contiene datos, como un cliente, una cuenta, o un item de inventario. Los beans de entidad contienen los valores de datos y los m�todos que se pueden invocar sobre esos valores. Los valores se salvan en una base de datos (que usa JDBC) o alg�n otro almac�n de datos. Los beans de entidad pueden participar en transacciones que implican otros beans enterprise y servicios transaccionales.
Los beans de entidad se asocian a menudo a objetos en bases de datos. Un bean de entidad puede representar una fila en un vector, una sola columna en una fila, o un resultado completo del vector o de la consulta. Asociado con cada bean de entidad hay una clave primaria �nica usada para encontrar, extraer, y grabar el bean.
Un bean de entidad puede emplear uno de los siguientes:
- Persistencia controlada por el bean. El bean contiene c�digo para extraer y grabar valores persistentes.
- Persistencia controlada por el contenedor. El contenedor EJB carga y graba valores en nombre del bean.
Cuando se utiliza la persistencia controlada por el contenedor, el compilador WebLogic EJB puede generar clases de soporte de JDBC para asociar un bean de entidad a una fila de una base de datos. Hay disponibles otros mecanismos de persistencia controlada por el contenedor. Por ejemplo, TOPLink para BEAWebLogic Server, de "The Object People" (http://www.objectpeople.com), proporciona persistencia para una base de datos de objetos relacionales.
Los beans de entidad pueden ser compartidos por muchos clientes y aplicaciones. Un ejemplar de un bean de entidad se puede crear a petici�n de cualquier cliente, pero no desaparece cuando ese cliente desconecta. Contin�a viviendo mientras cualquier cliente lo est� utilizando activamente. Cuando el bean ya no se usa, el contenedor EJB puede pasivizarlo: es decir, puede eliminar el ejemplar vivo del servidor.
�Beans de Sesi�n
Un bean de sesi�n es un ejemplar transitorio de EJB que sirve a un solo cliente. Los beans de sesi�n tienden a implementar l�gica de procedimiento; incorporan acciones en vez de datos. El contenedor EJB crea un bean de sesi�n en una petici�n del cliente. Entonces mantiene el bean mientras el cliente mantiene su conexi�n al bean. Los beans de sesi�n no son persistentes, aunque pueden salvar datos a un almac�n persistente si lo necesitan.
Un bean de sesi�n puede ser con o sin estado. Los beans de sesi�n sin estado no mantienen ning�n estado espec�fico del cliente entre llamadas y pueden ser utilizados por cualquier cliente. Pueden ser utilizados para proporcionar acceso a los servicios que no dependen del contexto de una sesi�n, como enviar un documento a una impresora o extraer datos de s�lo lectura en una aplicaci�n. Un bean de sesi�n con estado mantiene el estado en nombre de un cliente espec�fico.
Los beans de sesi�n con estado pueden ser utilizados para manejar un proceso, como ensamblar una orden o encaminar un documento con un flujo de proceso. Como pueden acumular y mantener el estado con interacciones m�ltiples con un cliente, los beans de sesi�n son a menudo la introducci�n a los objetos de una aplicaci�n. Como no son persistentes, los beans de sesi�n deben terminar su trabajo en una sola sesi�n y utilizar JDBC, JMS, o beans de entidad para registrar el trabajo permanentemente.
�Beans Dirigidos por Mensajes
Los beans dirigidos por Mensaje, introducidos en la especificaci�n EJB 2,0, son los beans enterprise que manejan los mensajes as�ncronos recibidos de colas de mensaje JMS. JMS encamina mensajes a un bean dirigido por mensaje, que selecciona un ejemplar de un almacen para procesar el mensaje.
Los beans dirigidos por Mensajes se manejan en el contenedor del servidor EJB de WebLogic. Como las aplicaciones dirigidas al usuario no los llaman directamente, no pueden ser accedidas desdee una aplicaci�n usando un EJB home. Sin embargo, una aplicaci�n dirigida al usuario si puede ejemplarizar un bean dirigidopor mensajes indirectamente, enviando un mensaje a la cola de bean JMS.
�Servicios de la Capa de Aplicaci�n
El servidor WebLogic proprociona los servicios fundamentales que permiten que los componentes se concentren en l�gica del negocio sin la preocupaci�n por detalles de implementaci�n de bajo nivel. Maneja el establecimiento de red, la autentificaci�n, la autorizaci�n, la persistencia, y el acceso a objetos remotos para EJBs y servlets. Los APIs Java est�ndar proporcionan acceso portable a otros servicios que una aplicaci�n puede utilizar, por ejemplo base de datos y servicios de mensajer�a.
Las aplicaciones cliente de tecnolog�as de comunicaci�n en la red conectan con el servidor WebLogic usando protocolos de establecimiento de una red est�ndar sobre TCP/IP. El servidor WebLogic escucha peticiones de conexi�n en una direcci�n de red que se pueda especificar como parte de un identificador de recuros uniforme (URI). Un URI es una cadena estandardizada que especifica un recurso en una red, incluyendo Internet. Contiene un especificador de protocolo llamado un esquema, la direcci�n de red del servidor, el nombre del recurso deseado, y los par�metros opcionales. La URL que introducimos en un navegador web, por ejemplo, http://www.bea.com/index.html, es el formato m�s familiar de URI.
Los clientes basados en Web se comunican con el servidor WebLogic usando el protocolo HTTP. Los clientes Java conectan usando Java RMI, que permite que un cliente Java ejecute objetos en servidor WebLogic. Los clientes CORBA tienen acceso a objetos RMI desde el servidor WebLogic usando RMI-IIOP, que le permite que ejecutar objetos del servidor WebLogic usando protocolos est�ndar de CORBA.
| Esquema | Protocolo |
|---|---|
| HTTP | HyperText Transfer Protocol. Utilizado por los navegadores Web y los programas compatibles HTTP. |
| HTTPS | HyperText Transfer Protoco over Secure Layers (SSL). Utilizado por programas de navegadores Web y clientes compatibles HTTPS. |
| T3 | Protocolo T3 de WebLogic para las conexiones de Java-a-Java, que multiplexa JNDI, RMI, EJB, JDBC, y otros servicios de WebLogic sobre una conexi�n de red. |
| T3S | Protocolo T3S de WebLogic sobre sockets seguros (SSL). |
| IIOP | Protocolo Internet de IIOP Inter-ORB, usado por los clientes de Java compatibles con CORBA para ejecutar objetos WebLogic RMI sobre IIOP. Otros clientes de CORBA conectan con el servidor WebLogic con un CORBA que nombra contexto en vez de un URI para las capas de la l�gica de WebLogic Server. |
El esquema en un URI determina el protocolo para los intercambios de la red entre un cliente y el servidor WebLogic. Los protocolos de red de la tabla 1-1.
Las secciones siguientes proporcionan m�s informaci�n sobre estos protocolos.
�HTTP
HTTP, el protocolo est�ndar del World Wide Web, es un protocolo de petici�n-respuesta. Un cliente publica una petici�n que incluya ana URI. La URI comienza con HTTP: / / y la direcci�n del servidor WebLogic, y el nombre de un recurso en el servidor WebLogic, como una p�gina html, un servlet, o una p�gina JSP. Si se omite el nombre del recurso, el servidor WebLogic devuelve la p�gina Web del valor por defecto, generalmente index.html. La cabecera de una petici�n HTTP incluye un comando, generalmente GET o POST. La petici�n puede incluir par�metros de datos y un mensaje de contenido.
WebLogic de BEA WebLogic responde siempre a una petici�n HTTP ejecutando un servlet, que devuelve resultados al cliente. Un servlet HTTP es una clase Java que puede tener acceso al contenido de una petici�n HTTP recibida sobre la red y devuelve al cliente un resultado compatible HTTP.
El servidor WebLogic dirige una petici�n de una p�gina HTML al servlet File interno. Este servlet busca el fichero HTML en el directorio de documentos del sistema de ficheros del servidor WebLogic. Una petici�n para un servlet personalizado ejecuta la clase Java correspondiente en el servidor WebLogic. Una petici�n de una p�gina JSP hace que el servidor WebLogic compile la p�gina JSP en un servlet, si no se ha compilado ya, y despu�s ejecuta el servlet, que devuelve los resultados al cliente.
�T3
T3 es un protocolo optimizado usado para transportar datos entre el servidor WebLogic y otros programas Java, incluyendo clientes y otros servidores WebLogic. El servidor WebLogic no pierde l apista de cada m�quina virtual Java (JVM) con que conecta, y crea una sola conexi�n T3 para llevar todo el tr�fico con una JVM.
Por ejemplo, si un cliente Java tiene acceso a un bean enterprise y a un almacen de conexiones JDBC en el servidor WebLogic, se establece una sola conexi�n de red entre el servidor WebLogic y la JVM del cliente. Los servicios de EJB y de JDBC pueden ser escritos como si tuvieran uso �nico de una conexi�n de red dedicada porque el protocolo T3 multiplexa invisiblemente los paquetes en la sola conexi�n. T3 es un protocolo eficiente para las aplicaciones Java-a-Java porque evita eventos innecesarios de conexi�n a red y utiliza pocos recursos del SO. El protocolo tambi�n tiene mejoras internas que reducen al m�nimo el tama�o de los paquetes.
�RMI
RMI es el recurso est�ndar de Java para las aplicaciones distribuidas. RMI permite que un programa Java, llamado el servidor, publique objetos Java que otro programa Java, llamado cliente, puede ejecutar. En la mayor�a de las aplicaciones, el servidor WebLogic es el servidor RMI y una aplicaci�n cliente Java es el cliente. Pero los papeles pueden ser invertidos; RMI permite que cualquier programa Java desempe�e el papel de servidor. La configuraci�n RMI es similar a la configuraci�n de CORBA. Para crear un objeto remoto, un programador escribe un interface para una clase Java que defina los m�todos que puede ejecutar un cliente remoto. El compilador RMI del servidor WebLogic, rmic, procesa el interface, produciendo clases Stubs RMI y esqueletos. La clase, los stubs, y los esqueletos remotos est�n instalados en servidor WebLogic.
Un cliente Java busca un objeto remotro en servidor WebLogic usando JNDI (Java Naming and Directory Interface), que se describe m�s adelante en esta secci�n. JNDI establece una conexi�n al servidor WebLogic, busca la clase remota , y devuelve los stubs al cliente.
El cliente ejecuta un m�todo del stub como si ejecutara el m�todo directamente en la clase remota. El m�todo del stub prepara la llamada y la transmite sobre la red a la clase esqueleto en el servidor WebLogic.
Sobre el servidor WebLogic, la clase esqueleto desempaqueta la petici�n y ejecuta el m�todo sobre el objeto del lado del servidor. Despu�s empaqueta los resultados y los devuelve al stub en la lado del cliente. WebLogic EJB y varios otros servicios disponibles para los clientes Java se construye en RMI. La mayor�a de las aplicaciones deben utilizar EJB en vez de usar RMI directamente, porque EJB proporciona una abstracci�n mejor para los objetos del negocio. Adem�s, el envase del servidor EJB de WebLogic proporciona a mejroas como almacenamiento en memoria inmediata, persistencia, y el control del ciclo vital que no est�n autom�ticamente disponibles para las clases remotas.
�RMI-IIOP
La Invocaci�n Remotra de M�todos sobre Inter-ORBProtocol Internet (RMI-IIOP) es un protocolo que permite que los programas clientes CORBA ejecuten objetos de WebLogic RMI, incluyendo beans enterprise. RMI-IIOP se basa en dos especificaciones del "Object Manegement Group" (http://www.omg.com):
- Mapeo Java-a-IDL.
- Objetos-por-valor.
La especificaci�n Java-a-IDL define c�mo un IDL se deriva de un interface Java. Los compiladores del servidor WebLogic para RMI y EJB le dan la opci�n de producir IDL al compilar objetos RMI y EJB. Este IDL se puede compilar con un compilador de IDL para producir los stubs requeridos por un cliente CORBA.
La especificaci�n del objeto-por-valor define c�mo los tipos de datos complejos se mapean entre Java y CORBA. Para utilizar objeto-por-valor, un cliente CORBA debe utilizar un ORB (Object Request Broker) con soporte de CORBA 2.3. Sin un ORB CORBA 2.3 los clientes CORBA s�lo pueden utilizar tipos primitivos de datos Java.
�SSL
El intercambio de datos con los protocolos HTTP y T3 se pueden encriptar con el SSL. Usando SSL asegura al cliente que ha conectado con un servidor autentificado y que los datos transmitidos sobre la red son privados. SSL utiliza el cifrado con clave p�blica, que requiere que compramos una ID de servidor, que es un certificado para nuestro servidor WebLogic, de una "Certificate Authority" como VeriSign. Cuando un cliente conecta puerto SSL del servidor WebLogic, el servidor y el cliente ejecutan un protocolo que incluya la autentificaci�n de las ID del servidor y la negociaci�n de los algoritmos y de los par�metros de cifrado para la sesi�n. El servidor WebLogic tambi�n se puede configurar para requerir que el cliente presente un certificado, un arreglo que se llama autentificaci�n mutua.
�Datos y Servicios de Acceso
El servidor WebLogic implementa tecnolog�as est�ndars J2EE para proporcionar servicos de datos y de acceso a las aplicaciones y a los componentes. Estos servicios incluyen los siguientes APIs:
- Java Naming and Directory Interface (JNDI)
- Java Database Connectivity (JDBC)
- Java Transaction API (JTA)
Las secciones siguientes explican estos servicios m�s detalladamente.
�JNDI
JNDI es un API est�ndar de Java que permite a las aplicaciones buscar un objeto por su nombre. El servidor WebLogic une los objetos Java que sirve a un nombre en un �rbol de nombres. Una aplicaci�n puede buscar objetos, como objetos RMI, JavaBeans Enterprise, colas JMS, y JDBC DataSources, obteniendo un contexto JNDI del servidor WebLogic y despu�s llamando el m�todo de operaciones de b�squeda JNDI con el nombre del objeto. Las operaciones de b�squeda devuelven una referencia al servidor de objetos WebLogic.
WebLogic JNDI soporta el balance de carga del cluster WebLogic. Todo servidor WebLogic en un cluster publica los objetos que sirve en un �rbol de nombres replicado en un amplio cluster. Una aplicaci�n puede obtener un contexto inicial JNDI del servidor fromany WebLogic en el cluster, realizar operaciones de b�squeda, y recibir una referencia del objeto desde cualquier servidor del cluster WebLogic que sirve el objeto. Se utiliza un algoritmo de balance de carga configurable separar la carga de trabajo entre los servidores del cluster.
�JDBC
La conectividad de la base de datos JDBC Java (JDBC) proporciona acceso a los recursos backend de base de datos. Las aplicaciones Java tienen acceso a JDBC usando un driver JDBC, que es un interface espec�fico del vendedor de la base de datos para un servidor de base de datos. Aunque cualquier aplicaci�n Java puede cargar un driver JDBC, conectar con la base de datos, y realizar operaciones de base de datos, el servidor WebLogic proporciona una ventaja de rendimiento significativa ofreciendo almacenes de conexi�n JDBC.
Un almacen de conexiones JDBC es un grupo se conexiones JDBC con nombre manejadas a trav�s del servidor WebLogic. En el momento de arranque el servidor WebLogic abre conexiones JDBC y las agrega al almacen. Cuando una aplicaci�n requiere una conexi�n JDBC, consigue una conexi�n del almacen, la utiliza, y luego la devulve al almacen para su uso por otras aplicaciones. Establecer una conexi�n con la base de datos es a menudo una operaci�n que consume mucho tiempo, y recrusos, un almacen de conexiones, que limita el n�mero de operaciones de la conexi�n, mejora su funcionamiento.
Para registar un almacen de conexiones en el �rbol de nombrado JNDIl, definimos un objeto DataSource para �l. Las aplicaciones clientes Java pueden entonces conseguir una conexi�n del almacen realizando operaciones de b�squeda JNDI con el nombre del DataSource.
las clases de Java del lado del Servidor utilizan el driver de conexiones JDBC de WebLogic JDBC, que es un driver gen�rico de JDBC que llama a trav�s al driver espec�fico del vendedr al driver JDBC. Este mecanismo hace el c�digo de la aplicaci�n m�s portable, incluso si cambiamos la marca de la base de datos usada en la grada backend.
El driver JDBC del lado del cliente es el driver de WebLogic JDBC/RMI, que es un interface RMI al driver del alamacen. Utilizamos este driver de la misma manera que utilizamos cualquier driver JDBC est�ndar. Cuando se utiliza el driver JDBC/RMI, los programas Java pueden tener acceso a JDBC de una manera consistente con otros objetos distribuidos en el servidor WebLogic, y pueden mantener las estructuras de datos de la base de datos en la capa media.
WebLogic EJB y WebLogic JMS tatan con conexiones de un almacen de conexiones JDBC para cargar y salvar objetos persistentes. Usando EJB y JMS, podemos conseguir a menudo una abstracci�n m�s �til de la que podemos obtener usando JDBC directamente en una aplicaci�n. Por ejemplo, usar un bean enterprise para representar un objeto de datos permite que cambiemmos el almac�n subyacente m�s adelante sin la modificaci�n del c�digo JDBC. Si utilizamos mensajes persistentes JMS en vez de operaciones de base de datos con JDBC, ser� m�s f�cil adaptar la aplicaci�n a un sistema de mensajer�a de una tercera persona m�s adelante.
�JTA
El API de transacci�n de Java (JTA) es el interface est�ndar para el manejo de transacciones en las aplicaciones Java. Usando transacciones, podemos proteger la integridad de los datos en nuestras bases de datos y manejar el acceso a esos datos por aplicaciones o ejemplares simult�neos de la aplicaci�n. Una vez que una transacci�n comienza, todas las operaciones transaccionales deben terminar con �xito o todas se deben deshacer.
El servidor WebLogic utiliza las transacciones que incluyen operaciones EJB, JMS, y JDBC. Las transacciones distribuidas, coordinadas con dos fases, pueden espandir m�ltiples bases de datos que son accedidas con los drivers XA-compliant JDBC, como BEA WebLogic jDriver para Oracle/XA.
La especificaci�n EJB define transaciones controladas por el bean y por el contenedor. Cuando se desarrolla un bean con transaciones controladas por el contenedor, el servidor WebLogic coordina la transacci�n autom�ticamente. Si se despliega un bean enterprise con transacciones manejadas por el bean, el programador de EJB debe proporcionar un c�digo de transacci�n.
El c�digo de aplicaci�n basado en los APIs JMS o JDBC puede iniciar una transacci�n, o participar en una transacci�n comenzada anteriormente. Un solo contexto de transacci�n se asocia con el thread de ejecuci�n de WebLogic Server, que ejecuta una aplicaci�n; todas las operaciones transaccionales realizadas en el thread participan en la transacci�n actual.
�Tecnolog�as de Mensajer�a
Las tecnolog�as de mensajer�a J2EE proporcionan un APIs est�ndar que las aplicaciones del servidor WebLogic pueden utilizar para comunicarse con una otra, as� como con aplicaciones de servidores no-WebLogic. Los servicios de mensajer�a incluyen los siguientes APIs:
- Java Message Service (JMS)
- JavaMail
Las secciones siguientes describen estos APIs con m�s detalle:
�JMS
El servicio de mensajer�a JMS de Java (JMS) permite a las aplicaciones comunicarse unas con otra intercambiando mensajes. Un mensaje es una petici�n, un informe, y/o un evento que contiene la informaci�n necesaria para coordinar la comunicaci�n entre diversas aplicaciones. Un mensaje proporciona un nivel de abstracci�n, permitiendo que separemos los detalles sobre el sistema de destino del c�digo de la aplicaci�n.
WebLogic JMS implementa dos modelos de mensajer�a: punto-a-punto (PTP) y publish/subscribe (pub/sub). El modelo PTP permite que cualquier n�mero de remitentes env�e mensajes a una cola. Cada mensaje en la cola se entrega a un solo programa de lectura. El modelo pub/sub permite que cualquier n�mero de remitentes env�e mensajes a un Topic. Cada mensaje en el Topic se env�a a todos los programas de lectura con una suscripci�n al Topic. Los mensajes se pueden entregar a los programas de lectura s�ncrona o as�ncronamente.
Los mensajes JMS pueden ser persistentes o no-persistentes. Los mensajes persistentes se salvan en una base de datos y no se pierden si se rearranca el servidor WebLogic. Los mensajes no-persistentes se pierden si se rearranca el servidor WebLogic. Los mensajes persistentes enviados a un Topic pueden conservarse hasta que todos los suscriptores interesados los hayan recibido.
JMS soporta varios tipos de mensaje que sonn �tiles para diversos tipos de aplicaciones. El cuerpo de mensaje puede contener los texto arbitrario, secuencias del bytes, tipos de datos primitivos de Java, parejas de nombre/valor, objetos serializables Java, o contenido XML.
�Javamail
El servidor JavaMail WebLogic incluye implementaci�n de referencia del Sun JavaMail. JavaMail permite que una aplicaci�n cree mensajes de E-mail y los env�e a trav�s de un servidor SMTP a la red.