Una de las razones por las que el desarrollo de un data warehouse crece r�pidamente, es que realmente es una tecnolog�a muy entendible. De hecho, data warehousing puede representar mejor la estructura amplia de una empresa para administrar los datos informacionales dentro de la organizaci�n. A fin de comprender c�mo se relacionan todos los componentes involucrados en una estrategia data warehousing, es esencial tener una Arquitectura Data Warehouse.
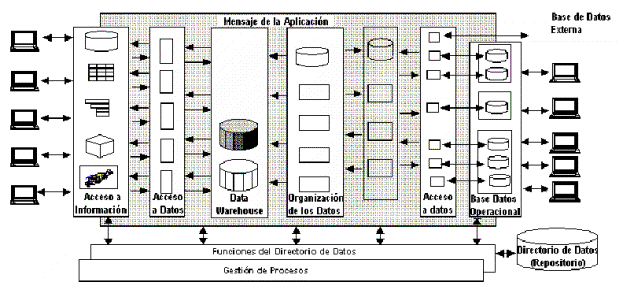
 �Elementos constituyentes de una Arquitectura Data Warehouse
�Elementos constituyentes de una Arquitectura Data Warehouse
Una Arquitectura Data Warehouse (Data Warehouse Architecture - DWA) es una forma de representar la estructura total de datos, comunicaci�n, procesamiento y presentaci�n, que existe para los usuarios finales que disponen de una computadora dentro de la empresa.
La arquitectura se constituye de un n�mero de partes interconectadas:
- Base de datos operacional / Nivel de base de datos externo
- Nivel de acceso a la informaci�n
- Nivel de acceso a los datos
- Nivel de directorio de datos (Metadata)
- Nivel de gesti�n de proceso
- Nivel de mensaje de la aplicaci�n
- Nivel de data warehouse
- Nivel de organizaci�n de datos
�Base de datos operacional / Nivel de base de datos externo
Los sistemas operacionales procesan datos para apoyar las necesidades operacionales cr�ticas. Para hacer eso, se han creado las bases de datos operacionales hist�ricas que proveen una estructura de procesamiento eficiente, para un n�mero relativamente peque�o de transacciones comerciales bien definidas.
Sin embargo, a causa del enfoque limitado de los sistemas operacionales, las bases de datos dise�adas para soportar estos sistemas, tienen dificultad al acceder a los datos para otra gesti�n o prop�sitos inform�ticos.
Esta dificultad en acceder a los datos operacionales es amplificada por el hecho que muchos de estos sistemas tienen de 10 a 15 a�os de antig�edad. El tiempo de algunos de estos sistemas significa que la tecnolog�a de acceso a los datos disponible para obtener los datos operacionales, es as� mismo antigua.
Ciertamente, la meta del data warehousing es liberar la informaci�n que es almacenada en bases de datos operacionales y combinarla con la informaci�n desde otra fuente de datos, generalmente externa.
Cada vez m�s, las organizaciones grandes adquieren datos adicionales desde bases de datos externas. Esta informaci�n incluye tendencias demogr�ficas, econom�tricas, adquisitivas y competitivas (que pueden ser proporcionadas por Instituciones Oficiales - INEI). Internet o tambi�n llamada "information superhighway" (supercarretera de la informaci�n) provee el acceso a m�s recursos de datos todos los d�as.
�Nivel de acceso a la informaci�n
El nivel de acceso a la informaci�n de la arquitectura data warehouse, es el nivel del que el usuario final se encarga directamente. En particular, representa las herramientas que el usuario final normalmente usa d�a a d�a. Por ejemplo: EXCEL, LOTUS 1-2-3, FOCUS, ACCESS, SAS, etc.
Este nivel tambi�n incluye el hardware y software involucrados en mostrar informaci�n en pantalla y emitir reportes de impresi�n, hojas de c�lculo, gr�ficos y diagramas para el an�lisis y presentaci�n. Hace dos d�cadas que el nivel de acceso a la informaci�n se ha expandido enormemente, especialmente a los usuarios finales quienes se han volcado a los PCS monousuarios y los PCS en redes.
Actualmente, existen herramientas m�s y m�s sofisticadas para manipular, analizar y presentar los datos, sin embargo, hay problemas significativos al tratar de convertir los datos tal como han sido recolectados y que se encuentran contenidos en los sistemas operacionales en informaci�n f�cil y transparente para las herramientas de los usuarios finales. Una de las claves para esto es encontrar un lenguaje de datos com�n que puede usarse a trav�s de toda la empresa.
�Nivel de acceso a los datos
El nivel de acceso a los datos de la arquitectura data warehouse est� involucrado con el nivel de acceso a la informaci�n para conversar en el nivel operacional. En la red mundial de hoy, el lenguaje de datos com�n que ha surgido es SQL. Originalmente, SQL fue desarrollado por IBM como un lenguaje de consulta, pero en los �ltimos veinte a�os ha llegado a ser el est�ndar para el intercambio de datos.
Uno de los adelantos claves de los �ltimos a�os ha sido el desarrollo de una serie de "filtros" de acceso a datos, tales como EDA/SQL para acceder a casi todo los Sistemas de Gesti�n de Base de Datos (Data Base Management Systems - DBMSs) y sistemas de archivos de datos, relacionales o no. Estos filtros permiten a las herramientas de acceso a la informaci�n, acceder tambi�n a la data almacenada en sistemas de gesti�n de base de datos que tienen veinte a�os de antig�edad.
El nivel de acceso a los datos no solamente conecta DBMSS diferentes y sistemas de archivos sobre el mismo hardware, sino tambi�n a los fabricantes y protocolos de red. Una de las claves de una estrategia data warehousing es proveer a los usuarios finales con "acceso a datos universales".
El acceso a los datos universales significa que, te�ricamente por lo menos, los usuarios finales sin tener en cuenta la herramienta de acceso a la informaci�n o ubicaci�n, deber�an ser capaces de acceder a cualquier o todos los datos en la empresa que es necesaria para ellos, para hacer su trabajo.
El nivel de acceso a los datos entonces es responsable de la interfaces entre las herramientas de acceso a la informaci�n y las bases de datos operacionales. En algunos casos, esto es todo lo que un usuario final necesita. Sin embargo, en general, las organizaciones desarrollan un plan mucho m�s sofisticado para el soporte del data warehousing.
�Nivel de Directorio de Datos (Metadata)
A fin de proveer el acceso a los datos universales, es absolutamente necesario mantener alguna forma de directorio de datos o repositorio de la informaci�n metadata. La metadata es la informaci�n alrededor de los datos dentro de la empresa.
Las descripciones de registro en un programa COBOL son metadata. Tambi�n lo son las sentencias DIMENSION en un programa FORTRAN o las sentencias a crear en SQL.
A fin de tener un dep�sito totalmente funcional, es necesario tener una variedad de metadata disponibles, informaci�n sobre las vistas de datos de los usuarios finales e informaci�n sobre las bases de datos operacionales. Idealmente, los usuarios finales deber�an de acceder a los datos desde el data warehouse (o desde las bases de datos operacionales), sin tener que conocer d�nde residen los datos o la forma en que se han almacenados.
�Nivel de Gesti�n de Procesos
El nivel de gesti�n de procesos tiene que ver con la programaci�n de diversas tareas que deben realizarse para construir y mantener el data warehouse y la informaci�n del directorio de datos. Este nivel puede depender del alto nivel de control de trabajo para muchos procesos (procedimientos) que deben ocurrir para mantener el data warehouse actualizado.
�Nivel de Mensaje de la Aplicaci�n
El nivel de mensaje de la aplicaci�n tiene que ver con el transporte de informaci�n alrededor de la red de la empresa. El mensaje de aplicaci�n se refiere tambi�n como "subproducto", pero puede involucrar s�lo protocolos de red. Puede usarse por ejemplo, para aislar aplicaciones operacionales o estrat�gicas a partir del formato de datos exacto, recolectar transacciones o los mensajes y entregarlos a una ubicaci�n segura en un tiempo seguro.
�Nivel Data Warehouse (F�sico)
En el data warehouse (n�cleo) es donde ocurre la data actual, usada principalmente para usos estrat�gicos. En algunos casos, uno puede pensar del data warehouse simplemente como una vista l�gica o virtual de datos. En muchos ejemplos, el data warehouse puede no involucrar almacenamiento de datos.
En un data warehouse f�sico, copias, en algunos casos, muchas copias de datos operacionales y/o externos, son almacenados realmente en una forma que es f�cil de acceder y es altamente flexible. Cada vez m�s, los data warehouses son almacenados sobre plataformas cliente/servidor, pero por lo general se almacenan sobre mainframes.
�Nivel de Organizaci�n de Datos
El componente final de la arquitectura data warehouse es la organizaci�n de los datos. Se llama tambi�n gesti�n de copia o r�plica, pero de hecho, incluye todos los procesos necesarios como seleccionar, editar, resumir, combinar y cargar datos en el dep�sito y acceder a la informaci�n desde bases de datos operacionales y/o externas.
La organizaci�n de datos involucra con frecuencia una programaci�n compleja, pero cada vez m�s, est�n cre�ndose las herramientas data warehousing para ayudar en este proceso. Involucra tambi�n programas de an�lisis de calidad de datos y filtros que identifican modelos y estructura de datos dentro de la data operacional existente.
�Operaciones en un Data Warehouse
En la Figura N� 8 se muestra algunos de los tipos de operaciones que se efect�an dentro de un ambiente data warehousing.
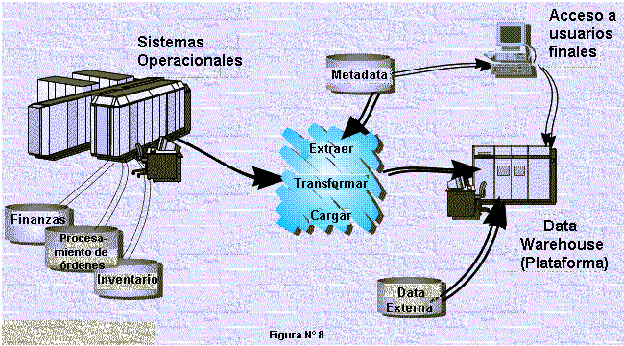
�Sistemas Operacionales
Los datos administrados por los sistemas de aplicaci�n operacionales son la fuente principal de datos para el data warehouse.
Las bases de datos operacionales se organizan como archivos indexados (UFAS, VSAM), bases de datos de redes/jer�rquicas (I-D-S/II, IMS, IDMS) o sistemas de base de datos relacionales (DB2, ORACLE, INFORMIX, etc.). Seg�n las encuestas, aproximadamente del 70% a 80% de las bases de datos de las empresas se organizan usando DBMSS no relacional.
�Extracci�n, Transformaci�n y Carga de los Datos
Se requieren herramientas de gesti�n de datos para extraer datos desde bases de datos y/o archivos operacionales, luego es necesario manipular o transformar los datos antes de cargar los resultados en el data warehouse.
Tomar los datos desde varias bases de datos operacionales y transformarlos en datos requeridos para el dep�sito, se refiere a la transformaci�n o a la integraci�n de datos. Las bases de datos operacionales, dise�adas para el soporte de varias aplicaciones de producci�n, frecuentemente difieren en el formato.
Los mismos elementos de datos, si son usados por aplicaciones diferentes o administrados por diferentes software DBMS, pueden definirse al usar nombres de elementos inconsistentes, que tienen formatos inconsistentes y/o ser codificados de manera diferente. Todas estas inconsistencias deben resolverse antes que los elementos de datos sean almacenados en el data warehouse.
�Metadata
Otro paso necesario es crear la metadata. La metadata (es decir, datos acerca de datos) describe los contenidos del data warehouse. La metadata consiste de definiciones de los elementos de datos en el dep�sito, sistema(s) del (os) elemento(s) fuente. Como la data, se integra y transforma antes de ser almacenada en informaci�n similar.
�Acceso de usuario final
Los usuarios acceden al data warehouse por medio de herramientas de productividad basadas en GUI (Graphical User Interface - Interface gr�fica de usuario). Pueden proveerse a los usuarios del data warehouse muchos de estos tipos de herramientas.
Estos pueden incluir software de consultas, generadores de reportes, procesamiento anal�tico en l�nea, herramientas data/visual mining, etc., dependiendo de los tipos de usuarios y sus requerimientos particulares. Sin embargo, una sola herramienta no satisface todos los requerimientos, por lo que es necesaria la integraci�n de una serie de herramientas.
�Plataforma del data warehouse
La plataforma para el data warehouse es casi siempre un servidor de base de datos relacional. Cuando se manipulan vol�menes muy grandes de datos puede requerirse una configuraci�n en bloque de servidores UNIX con multiprocesador sim�trico (SMP) o un servidor con procesador paralelo masivo (MPP) especializado.
Los extractos de la data integrada/transformada se cargan en el data warehouse. Uno de los m�s populares RDBMSs disponibles para data warehousing sobre la plataforma UNIX (SMP y MPP) generalmente es Teradata. La elecci�n de la plataforma es cr�tica. El dep�sito crecer� y hay que comprender los requerimientos despu�s de 3 o 5 a�os.
Muchas de las organizaciones quieran o no escogen una plataforma por diversas razones: el Sistema X es nuestro sistema elegido o el Sistema Y est� ya disponible sobre un sistema UNIX que nosotros ya tenemos. Uno de los errores m�s grandes que las organizaciones cometen al seleccionar la plataforma, es que ellos presumen que el sistema (hardware y/o DBMS) escalar� con los datos.
El sistema de dep�sito ejecuta las consultas que se pasa a los datos por el software de acceso a los datos del usuario. Aunque un usuario visualiza las consultas desde el punto de vista de un GUI, las consultas t�picamente se formulan como pedidos SQL, porque SQL es un lenguaje universal y el est�ndar de hecho para el acceso a datos.
�Datos Externos
Dependiendo de la aplicaci�n, el alcance del data warehouse puede extenderse por la capacidad de acceder a la data externa. Por ejemplo, los datos accesibles por medio de servicios de computadora en l�nea (tales como CompuServe y America On Line) y/o v�a Internet, pueden estar disponibles a los usuarios del data warehouse.
�Evoluci�n del Dep�sito
Construir un data warehouse es una tarea grande. No es recomendable emprender el desarrollo del data warehouse de la empresa como un proyecto cualquiera. M�s bien, se recomienda que los requerimientos de una serie de fases se desarrollen e implementen en modelos consecutivos que permitan un proceso de implementaci�n m�s gradual e iterativo.
No existe ninguna organizaci�n que haya triunfado en el desarrollo del data warehouse de la empresa, en un s�lo paso. Muchas, sin embargo, lo han logrado luego de un desarrollo paso a paso. Los pasos previos evolucionan conjuntamente con la materia que est� siendo agregada.
Los datos en el data warehouse no son vol�tiles y es un repositorio de datos de s�lo lectura (en general). Sin embargo, pueden a�adirse nuevos elementos sobre una base regular para que el contenido siga la evoluci�n de los datos en la base de datos fuente, tanto en los contenidos como en el tiempo.
Uno de los desaf�os de mantener un data warehouse, es idear m�todos para identificar datos nuevos o modificados en las bases de datos operacionales. Algunas maneras para identificar estos datos incluyen insertar fecha/tiempo en los registros de base de datos y entonces crear copias de registros actualizados y copiar informaci�n de los registros de transacci�n y/o base de datos diarias.
Estos elementos de datos nuevos y/o modificados son extra�dos, integrados, transformados y agregados al data warehouse en pasos peri�dicos programados. Como se a�aden las nuevas ocurrencias de datos, los datos antiguos son eliminados. Por ejemplo, si los detalles de un sujeto particular se mantienen por 5 a�os, como se agreg� la �ltima semana, la semana anterior es eliminada.