Los datos operacionales y los datos del data warehouse son accedidos por usuarios que usan los datos de maneras diferentes.
| Uso de Base de Datos Operacionales | Uso de Data Warehouse |
|---|---|
| Muchos usuarios concurrentes | Pocos usuarios concurrentes |
| Consultas predefinidas y actualizables | Consultas complejas, frecuentemente no anticipadas. |
| Cantidades peque�as de datos detallados | Cantidades grandes de datos detallados |
| Requerimientos de respuesta inmediata | Requerimientos de respuesta no cr�ticos |
- Maneras diferentes de uso de datos
-
Los usuarios de un data warehouse necesitan acceder a los datos complejos, frecuentemente desde fuentes m�ltiples y de formas no predecibles.
Los usuarios que accedan a los datos operacionales, com�nmente efect�an tareas predefinidas que, generalmente requieren acceso a una sola base de datos de una aplicaci�n. Por el contrario, los usuarios que accedan al data warehouse, efect�an tareas que requieren acceso a un conjunto de datos desde fuentes m�ltiples y frecuentemente no son predecibles. Lo �nico que se conoce (si es modelada correctamente) es el conjunto inicial de datos que se han establecido en el dep�sito.
Por ejemplo, un especialista en el cuidado de la salud podr�a necesitar acceder a los datos actuales e hist�ricos para analizar las tendencias de costos, usando un conjunto de consultas predefinidas. Por el contrario, un representante de ventas podr�a necesitar acceder a los datos de cliente y producto para evaluar la eficacia de una campa�a de marketing, creando consultas base o ad-hoc para encontrar nuevamente necesidades definidas.
- Maneras diferentes de uso de datos
S�lo pocos usuarios acceden a los datos concurrentemente
- Los usuarios generan un procesamiento no predecible complejo
-
Los usuarios del data warehouse generan consultas complejas. A veces la respuesta a una consulta conduce a la formulaci�n de otras preguntas m�s detalladas, en un proceso llamado drilling down. El data warehouse puede incluir niveles de res�menes m�ltiples, derivado de un conjunto principal, �nico, de datos detallados, para soportar este tipo de uso.
En efecto, los usuarios frecuentemente comienzan buscando en los datos resumidos y como identifican �reas de inter�s, comienzan a acceder al conjunto de datos detallado. Los conjuntos de datos resumidos representan el "Qu�" de una situaci�n y los conjuntos de datos detallados permiten a los usuarios construir un cuadro sobre "C�mo" se ha derivado esa situaci�n.
- Las consultas de los usuarios accedan a cantidades grandes de datos
Debido a la necesidad de investigar tendencias y evaluar las relaciones entre muchas clases de datos, las consultas al data warehouse permiten acceder a vol�menes muy grandes tanto de data detallada como resumida. Debido a los requerimientos de datos hist�ricos, los data warehouses evolucionan para llegar a un tama�o m�s grande que sus or�genes operacionales (de 10 a 100 veces m�s grande).
- Las consultas de los usuarios no tienen tiempos de respuesta cr�ticos
-
Las transacciones operacionales necesitan una respuesta inmediata porque un cliente puede estar esperando una respuesta. En el data warehouse, por el contrario, tiene un requerimiento de respuesta no cr�tico porque el resultado frecuentemente se usa en un proceso de an�lisis y toma de decisiones. Aunque los tiempos de respuesta no son cr�ticos, los usuarios esperan una respuesta dentro del mismo d�a en que es hecha la consulta.
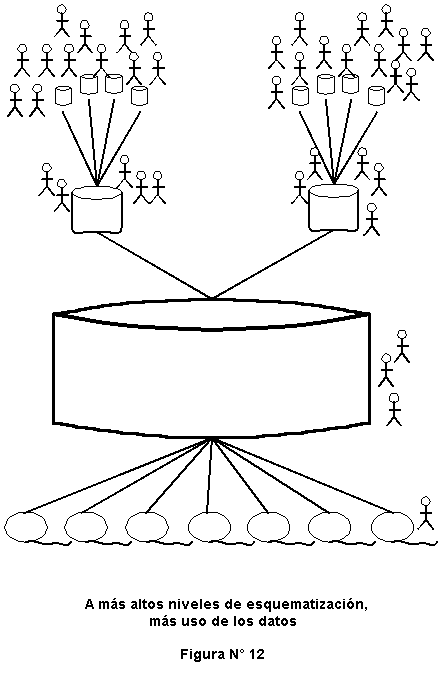
Por lo general, los diferentes niveles de datos dentro del data warehouse reciben diferentes usos. A m�s alto nivel de esquematizaci�n, se tiene mayor uso de los datos.
En la Figura N� 12 se muestra que hay mayor uso de los datos completamente resumidos, a diferencia de la informaci�n antigua que apenas es usada.
Hay una buena raz�n para mover una organizaci�n al paradigma sugerido en la figura, la utilizaci�n del recurso. La data m�s resumida, permite capturar los datos en forma m�s r�pida y eficiente. Si en una tarea se encuentra que se hace mucho procesamiento a niveles de detalle del data warehouse, entonces se consumir� muchos recursos de m�quina. Es mejor hacer el procesamiento a niveles m�s altos de esquematizaci�n como sea posible.
Para muchas tareas, el analista de sistemas de soporte de decisiones usa la informaci�n detallada en un pre data warehouse. La seguridad de la informaci�n de detalle se consigue de muchas maneras, aun cuando est�n disponibles otros niveles de esquematizaci�n. Una de las actividades del dise�ador de datos es el de desconectar al usuario del sistema de soporte de decisiones del uso constante de datos con un detalle m�s bajo.
El dise�ador de datos tiene dos predisposiciones:
- Instalar un sistema chargeback, donde el usuario final pague por los recursos consumidos
- Se�alar el mejor tiempo de respuesta que puede obtenerse cuando se trabaja con la data a un nivel alto de esquematizaci�n, a diferencia de un pobre tiempo de respuesta que resulta de trabajar con los datos a un nivel bajo de detalle.
Para ilustrar c�mo un data warehouse puede ayudar a una organizaci�n a mejorar sus operaciones, se muestra un ejemplo de lo que es el desarrollo de actividades sin tener un data warehouse.
- Ejemplo: Preparaci�n de un reporte complejo
-
Considere un problema bastante t�pico en una compa��a de fabricaci�n grande en el que se pide una informaci�n (un reporte) que no est� disponible.
El informe incluye las finanzas actuales, el inventario y la condici�n de personal, acompa�ado de comparaciones del mes actual con el anterior y el mismo mes del a�o anterior, con una comparaci�n adicional de los 3 a�os precedentes. Se debe explicar cada desviaci�n de la tendencia que cae fuera de un rango predefinido.
Sin un data warehouse, el informe es preparado de la manera siguiente:
La informaci�n financiera actual se obtiene desde una base de datos mediante un programa de extracci�n de datos, el inventario actual de otro programa de extracci�n de otra base de datos, la condici�n actual de personal de un tercer programa de extracci�n y la informaci�n hist�rica desde una copia de seguridad de cinta magn�tica o CD-ROM.
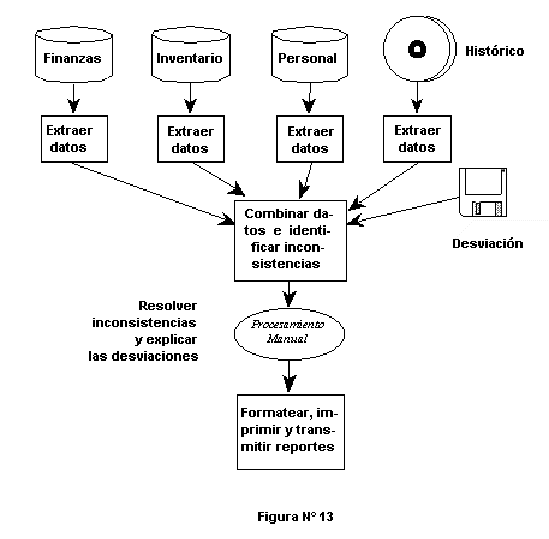
Lo m�s interesante es que se ha pedido otro informe que contin�e al primer informe (debido a que las preguntas se originaron a partir del anterior). El hecho es, que ninguno de los trabajos realizados hasta aqu� (por ejemplo, diversos programas de extracci�n) se pueden usar para los pr�ximos o para cualquier reporte subsiguiente. Imagine el tiempo y el esfuerzo que se ha desperdiciado por un enfoque anticuado. (Ver Figura N� 13).
Las inconsistencias deben identificarse en cada conjunto de datos extra�dos y resolverse, por lo general, manualmente. Cuando se completa todo este procesamiento, el reporte puede ser formateado, impreso, revisado y transmitido.
Nuevamente, el punto importante aqu� es que todo el trabajo desempe�ado para hacer este informe no afecta a otros reportes que pueden solicitarse es decir, todos ellos son independientes y caros, desde el punto de vista de recursos y productividad.
Al crear un data warehouse y combinar todos los datos requeridos, se obtienen los siguientes beneficios:
Las inconsistencias de los datos se resuelven autom�ticamente cuando los elementos de datos se cargan en el data warehouse, no manualmente, cada vez que se prepara un reporte.
Los errores que ocurrieron durante el proceso complejo de la preparaci�n del informe, se minimizan porque el proceso es ahora mucho m�s simple.
Los elementos de datos son f�cilmente accesibles para otros usos, no s�lo para un reporte particular.
Se crea una sola fuente.